AI in a Shell
Posted on February 23, 2025 (Last modified on February 24, 2025) • 8 min read • 1,688 wordsChat in Documentation

We Created an AI Chatbot
So What?
There are two kinds of people in the world: those who write documentation, hoping others will read and understand it, and those who need information but struggle to find it in massive, complex manuals. Unfortunately, the reality is that documentation often becomes overwhelming, and users looking for a simple answer can easily get lost. This is why most electronic documentation systems include at least a basic search function.
To be honest, the initial version of the CERIT-SC Kubernetes documentation lacked this feature. But even with a search function, users must know what to look for and often need to input the exact phrasing to find relevant results.
If you’re already familiar with RAG concepts, feel free to skip ahead to the Implementation section.
AI to the Rescue?
With rapid advancements in artificial intelligence, particularly in Large Language Models (LLMs), the way we interact with information is evolving. LLMs can engage in human-like conversations on a wide range of topics they’ve been trained on. This led to the idea: what if we could train an LLM specifically on our documentation, allowing it to answer questions conversationally?
However, training an entire LLM from scratch is incredibly time-consuming and resource-intensive. Worse, trained models can sometimes generate inaccurate or entirely fabricated answers (a phenomenon known as “hallucination”). An alternative is fine-tuning—where we refine an existing LLM with additional data. While this is significantly easier than full-scale training, it still carries risks, such as inaccuracies and “catastrophic forgetting,” where the model loses previously learned knowledge.
RAG: A Smarter Approach
Fortunately, there’s a more efficient method: Retrieval-Augmented Generation (RAG). Instead of training or fine-tuning the model, RAG dynamically retrieves relevant documentation and provides context-aware responses. Essentially, it combines the power of AI with real-time access to authoritative information, reducing the risk of hallucination while keeping the system up to date.
Well, in principle, it is. The typical workflow of a RAG system looks like this:
- Collect the relevant documents.
- Generate document embeddings using an embedding model (a specialized AI that converts text into numerical vectors).
- Store these embeddings in a database.
- Take a user’s request.
- Generate an embedding for the request using the same embedding model.
- Perform a similarity search to find the most relevant stored embeddings.
- Retrieve the top matches and use them as context for a general-purpose LLM to generate a response. The number of retrieved documents is usually denoted as
top_k.
However, there are some limitations. The most significant one is the context size limit in LLMs. Modern large models support around 128k to 200k tokens per request. For rough estimation, one token is approximately four characters, meaning the maximum usable context size is around 512KB to 800KB of text.
More Isn’t Always Better
At first glance, 800KB of context might seem like more than enough for anyone. However, there’s a catch: attention dilution. The larger the context window, the more the model’s attention gets spread out, making it harder to focus on specific details. If too much irrelevant text is included, the model may miss critical information.
Thus, optimizing the amount of context is crucial—too little might lead to incomplete answers, while too much could reduce accuracy. Striking the right balance is key.
Context: Nothing Else Matters
Ultimately, the effectiveness of RAG depends on providing the right context—no more, no less. Proper document selection, retrieval tuning, and efficient context management are what make the difference between an AI assistant that truly helps and one that gets lost in the noise.
For shorter texts, we could theoretically use the entire text as context. However, even with short documents, there’s a major constraint: the context size limit of the embedding model. And the situation here is quite restrictive. Some embedding models support as little as 500 tokens (about 2,000 characters), while others allow 1,000 to 8,000 tokens. A few larger models offer 32k-token context windows, but these models are significantly larger in size, requiring more memory and computational resources. In contrast, smaller-context models are more lightweight and efficient.
Embedding Model Limitations
Another key factor is embedding dimensions, which determine how much information can be stored in an embedding vector. This refers to the number of numerical values in the vector representation of the text. Typical embedding models have fewer than 4,000 dimensions, with some exceptions reaching around 9,000. However, compressing a 32k-token document into a 9,000-dimension vector inevitably leads to information loss, which can reduce the accuracy of similarity searches.
Language support is another critical consideration. Most embedding models are optimized for English, but if you need to process other languages—such as Czech—you’ll need a model trained on that language or a multilingual embedding model.
For details on different embedding models, their context sizes, and relative performance, check the Hugging Face embedding models leaderboard.
Document Splitting: The Key to Effective Retrieval
If we are limited to models with 500-1,000 token context windows, even short texts may need to be split into smaller chunks. Proper document splitting is crucial: each chunk should contain enough information to enable effective similarity searches while remaining within the model’s constraints.
While manually splitting text would likely yield the best results, it’s impractical—especially for documentation that frequently updates. Automatic splitting is a challenging problem, and there isn’t a universally effective “magic text splitter.”
Since many documentation systems use Markdown, we can leverage libraries that understand Markdown structure and split the text accordingly. A best practice is to allow overlapping chunks to ensure that relevant context isn’t lost at chunk boundaries.
For more on Markdown-based text splitting, check out the MarkdownTextSplitter.
Additionally, you can explore various text splitting experiments in this Jupyter Notebook.
Implementation
Let’s dive into the implementation, which is composed of several key components: the Embedder, the Embedding API and database, and the chat interface.
The Embedder
We developed a simple embedder for our Markdown documentation in MDX format, utilizing MarkdownTextSplitter for text segmentation. The implementation is available on the CERIT-SC GitHub repository. It is designed to work with documentation following the Fumadocs structure.
We also extended the usual metadata collected for each document to enhance searchability and retrieval. Specifically, we store:
- Document title – Extracted directly from the MDX format, allowing for better display in search results.
- Chunk number – Helps reconstruct a broader context when needed.
- Language – Indicates the language of the document for multilingual support.
- Path – The relative URL of the document on the web, enabling direct source linking.
The Embedding API and Database
For our embedding API, we utilized the Embedbase project. Besides a paid API, it also provides an open-source implementation available on GitHub, allowing for self-hosting. The Embedbase requires access to a database and certain AI model APIs.
We made some modifications to the code, as it includes built-in support for authentication tokens, which wasn’t necessary for our internal use, given our IP-limited access. Additionally, we addressed database support. By default, Embedbase utilizes
Supabase, which offers both a paid service and a free self-hosted option. The self-hosted setup can be complex, ultimately running a PostgreSQL database with the pg_vector extension. Fortunately, Embedbase also supports direct connection to PostgreSQL, making it feasible to directly deploy a PostgreSQL instance and integrate it with Embedbase. However, it’s important to note that the PostgreSQL configuration in Embedbase is marked as experimental and requires specifying the number of vector dimensions in advance.
The original version of Embedbase supports the OpenAI API and Cohere API. For the OpenAI API, it uses an older Python module, which does not support connecting to various OpenAI API compatible providers.
Final Modifications:
- Removed
Firebaseauthentication. - Updated the
OpenAImodule to the latest version, which allows specifying the base URL for the OpenAI API. This update enables the use of local OpenAI-compatible deployments, such asOllama. - Enhanced the PostgreSQL module to retry communication with the database in case of connection drops, such as during a server restart. We also added the capability to assemble a complete text document from chunks, facilitating the provision of a full document as context.
For the database, we deployed a simple PostgreSQL instance using our Kubernetes
CloudNativePG operator and enabled the pg_vector extension.
Note: If we want to experiment with a different embedding model, the entire setup must be redeployed, as embeddings from different models are not compatible and vector dimensions vary, which necessitates different SQL table schemas.
The Docker file and Kubernetes deployment script are available on our GitHub repository.
Chat Interface
We leveraged the chat implementation from Fumadocs. Since it natively supports only the Inkeep AI API, we modified the component to work with the OpenAI API and integrated embedding functionality.
The chat flow operates as follows:
- If the given prompt is the first question, an embedding context is created, appended to the prompt, and sent to the LLM.
- Otherwise, the message is sent directly to the LLM along with the full conversation history (questions and answers), enabling users to ask detailed follow-up questions.
Additionally, we implemented three answer-generation variants:
- Local embeddings combined with the OpenAI GPT-4o-mini model.
- Local embeddings combined with the local LLaMA 3.3 model.
- A local DeepSeek R1 model with a fixed context about our local Kubernetes infrastructure and related components (such as Docker and Helm) for answering generic questions.
For embeddings, we experimented with the following models:
mxbai-embed-large:latestnomic-embed-text:latest
The chat interface implementation can be found in our
GitHub repository under the components/ai folder.
Results
If you have a valid MetaCentrum account, you can try the chat interface yourself at https://docs.cerit.io.
Below are some example interactions to give you a preview:
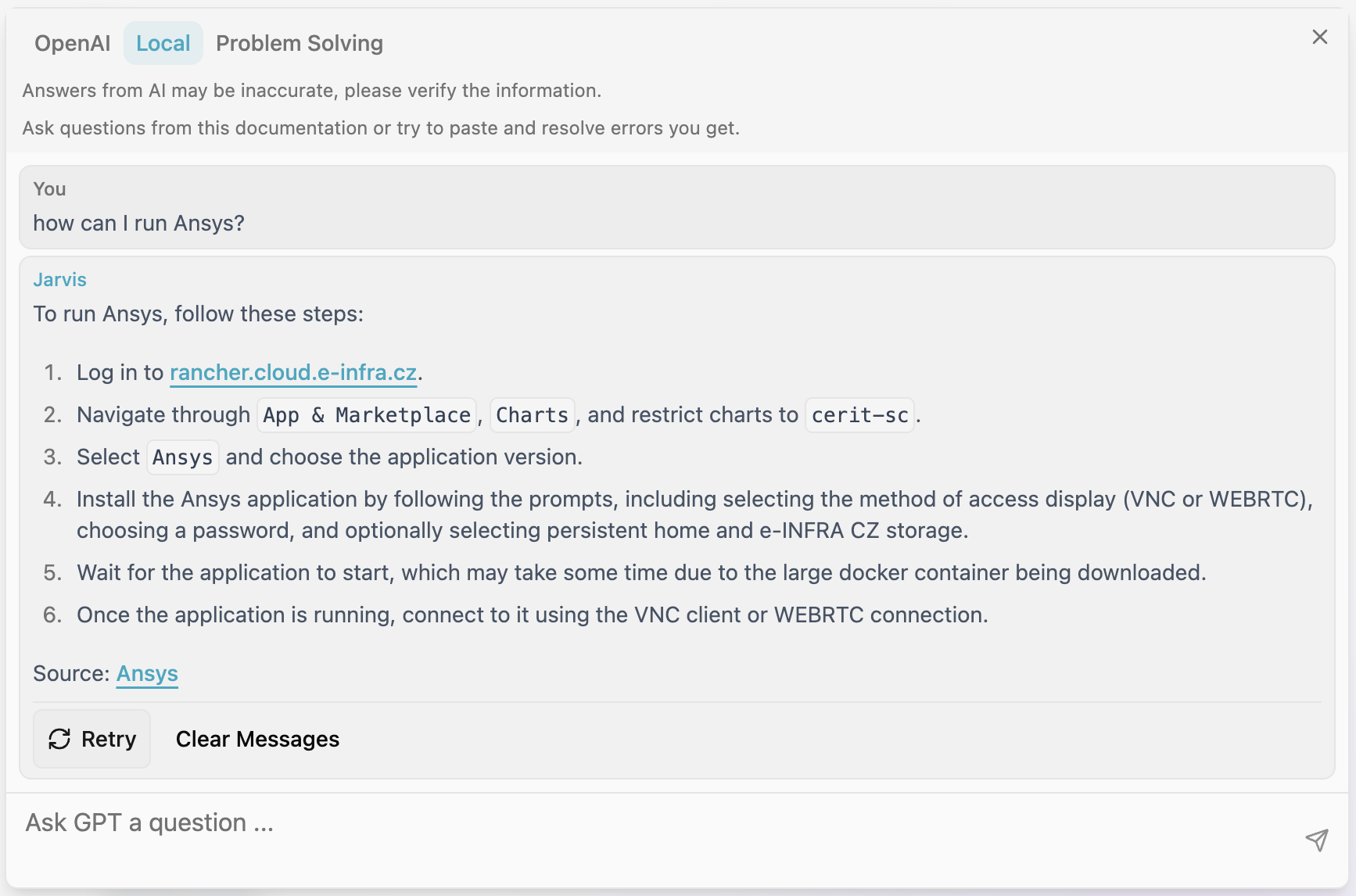
Chat question about Ansys, evaluated by the LLaMA model:
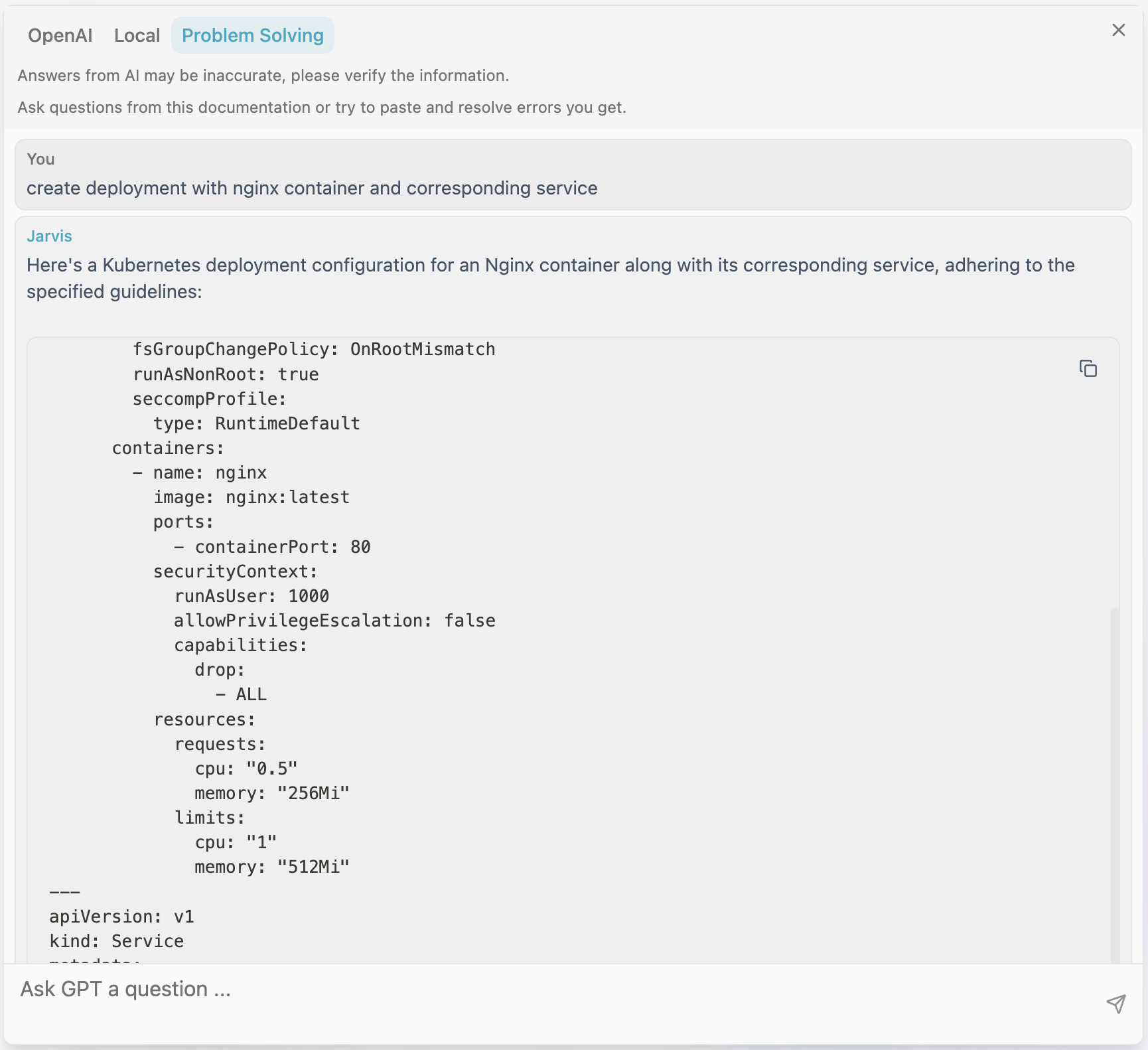
Generic chat question about Deployment, evaluated by the DeepSeek R1 model:
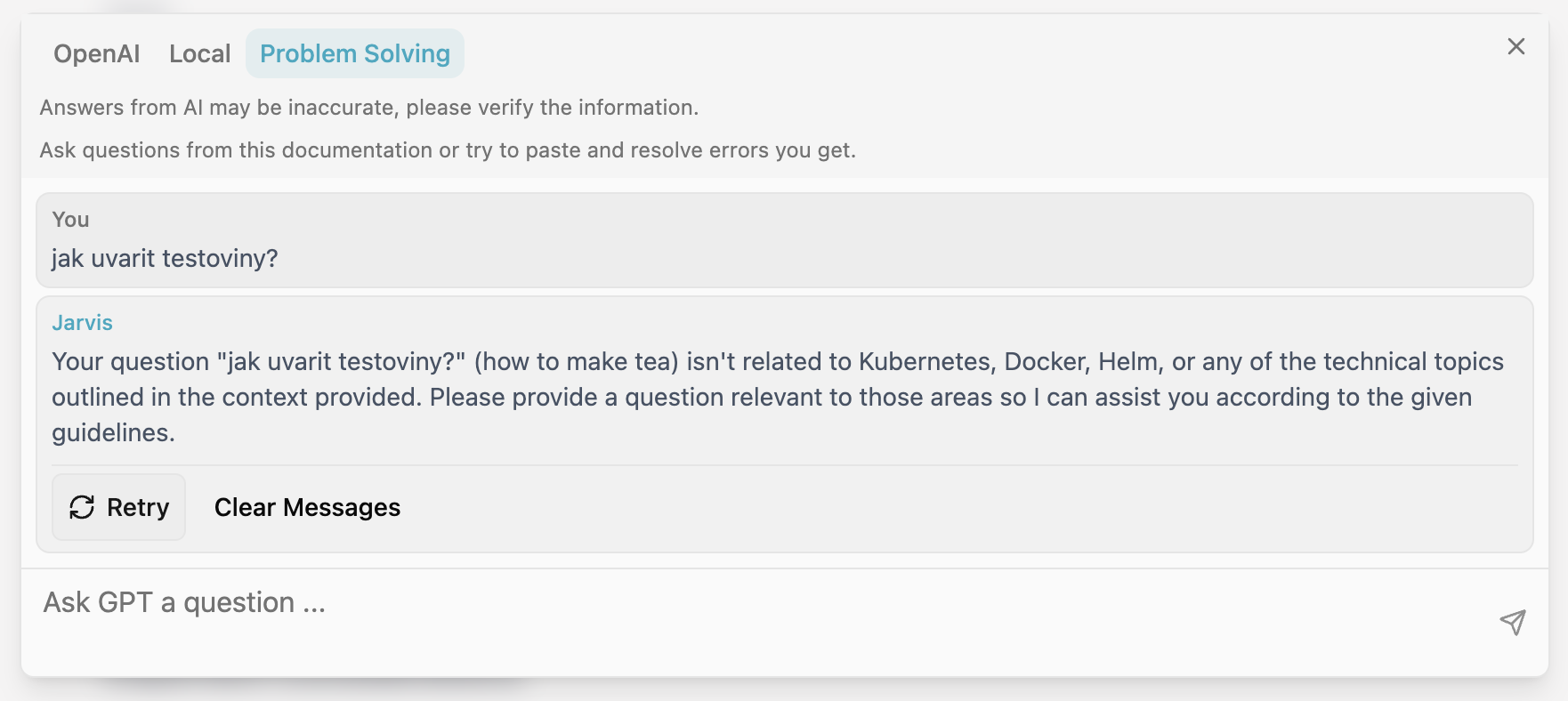
Occasionally, responses may not be as expected—especially due to the limitations of Czech language support in LLMs:

And just to clarify—we don’t cook pasta:
Final Thoughts
- Further benchmarking and evaluation of various models, particularly multilingual ones, will be necessary.
- Exploring advanced techniques such as re-ranking and multi-agentic RAG is an ongoing area of interest.
- Fine-tuning embedding models is also under consideration, especially for non-English languages.