AI docs search
Posted on June 27, 2025 (Last modified on June 30, 2025) • 8 min read • 1,682 wordsTesting embedding models with CERIT-SC documentation.

Embedders
To understand the context, please read this article from February, where we learned about how we implemented embedders to improve chatbots using RAG. Here we describe our next steps.
We experimented with a wider range of embedding models, as many different options are available. We wanted to see which embedding model is best suited to our purpose:
To find the embedding model that best returns the most relevant parts of the CERIT-SC documentation for a user’s question, so the chatbot can use them to provide a helpful answer.
For example, when asking the chatbot “How can I access Omero from the command line?”, the embedder should return the most relevant documents (Omero.dmx, Kubectl.mdx,…) that the chatbot can then use to answer the query. Ideally, the Omero.mdx would be on the first position as most relevant.
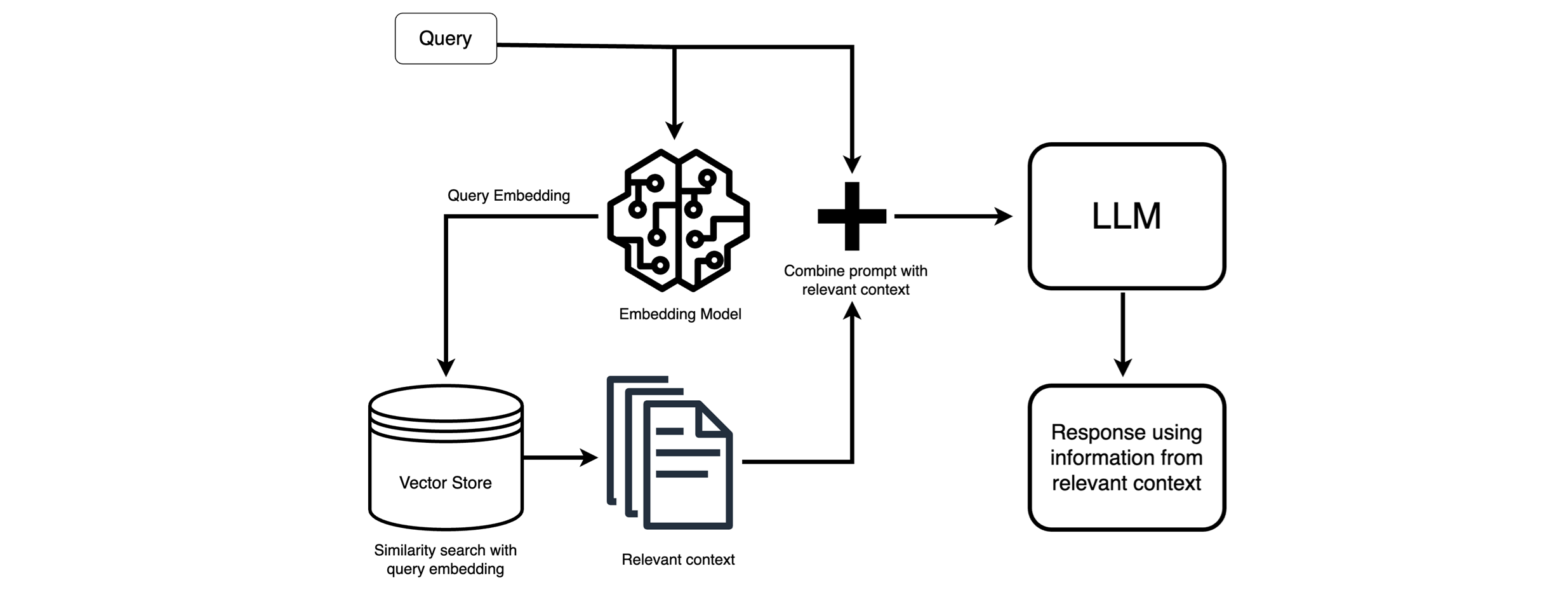
How do embedders differ?
Embedders vary in many aspects like architecture, language support, context window size (tokens) or vector dimensionality. For example, multilingual-e5-large-instruct gives 1024-dimensional embeddings, supports about 512 tokens, and works across 90+ languages, while nomic-embed-text-v1.5 offers flexible dimensions (64–768), handles up to 8192 tokens, and is optimized for both short and long texts in many languages. Some models are trained broadly on internet text, others on specialized domains like code or documentation – it is not always a simple decision which model is the best for a given purpose.
In the case of our database (
pgvector), longer vectors are problematic, because the indexing is not supported for them – and it makes the search slower.
These differences affect how well the embedders capture context and retrieve relevant chunks. Multilingual support matters if queries include Czech terms; vector length impacts storage and search speed.
What we did
Models
We tested these models below. The ones from OpenAI are paid (roughly $0.02–$0.13 for processing 7,500 prompts, each around 100 words), the other models are open-source.
| Name | Provider | Dimensions |
|---|---|---|
| text-embedding-3-small | OpenAI | 1536 |
| text-embedding-3-large | OpenAI | 3072 |
| text-embedding-ada-002 | OpenAI | 1536 |
| mxbai-embed-large:latest | Mixedbread | 1024 |
| jina-embeddings-v3 | Jina | 1024 |
| multilingual-e5-large-instruct | intfloat | 1024 |
| nomic-embed-text-v1.5 | Nomic | 768 |
| qwen3-embedding-4b | Alibaba/Qwen | 2560 |
Testing methodology
Testing datasets
We created our custom testing dataset both for Czech and English – we decided to simulate user’s questions by asking a GPT-4o to generate questions that can be answered using mainly a specific document (by document we mean a single mdx file from CERIT-SC documentation). The dataset consists of 5 questions for each document. There are separate datasets for both languages and different style, see the examples in the table below. The first two question variants were quite specific and long, the other two were intended to simulate real user’s behavior by using shor prompts or incomplete sentences.
| Variant | Czech | English |
|---|---|---|
| 1 | Jakým způsobem je možné nasadit databázi Postgres pro aplikaci Omero v Kubernetes? | How do you create a secret for the Postgres database user and password for Omero? |
| 2 | Jaké jsou dvě hlavní komponenty potřebné pro spuštění aplikace Omero v Kubernetes? | Why is the second option of running Omero images manually preferred for Kubernetes over using docker-compose? |
| 3 | Co dělat, když je databáze pomalá při zpracování zátěže? | Postgres random password vs explicit password? |
| 4 | omero web ingress konfigurace | omero docker options |
The embedder was then given the question, and returned 5 most relevant documents using the cosine similarity metric. We assumed that only one document was relevant, although in reality the answer may partially be found in more of these (or at least in both Czech and English copy of the same content). The ground truth were generated questions described above.
Metrics
For evaluation, we used a single metric: Mean Reciprocal Rank at 5 (MRR@5).
MRR@5 = (1 / N) * Σ (1 / rank)
- N is the total number of queries.
- rank is the position (1 to 5) of the correct document in the top 5 results.
- If the correct document is not in the top 5, the reciprocal rank is 0.
This showed us how well the embedder ranked the correct document among the top 5 results. If the correct document is ranked 1st, it gets a score of 1.0; if it’s 2nd, the score is 0.5; 3rd is 0.33, and so on. If the correct document is not in the top 5, the score is 0.
We chose MRR@5 because it not only checks if the correct document is found, but also rewards placing it higher in the results – giving us a better sense of ranking quality than simple recall.
Visualization
To visualize the embeddings, we applied Principal Component Analysis (PCA) to reduce the high-dimensional embeddings down to two dimensions for plotting. PCA helps reveal how embeddings are distributed in space by projecting them along the directions that capture the most variance. While it simplifies the structure a lot (e.g. from 1024 to 2 dimensions), it gives a useful approximation of how close or distant points are in the original space.
Implementation
We continued with the same implementation as
before, using API and PostgreSQL with pg_vector extension – the only change was that we stored vectors of different dimensionality in the same database.
We also added automatic language detection – if the query language was Czech, the db search space was pruned to only Czech language, which was expected to both improve the results and to speed up the search a little. For that we used langdetect library. After recognizing the language, a “where” clause was added to search query used for retrieving documents. This filtering was applied after the database returned results, so sometimes fewer than the requested number of documents were ultimately included in the final result set.
Note: Although the system requests the top 5 results (
top_k = 5) from the database, the final output may contain fewer than 5 documents. This happens because multiple top-ranked chunks may belong to the same original document (identified by the samemetadata['path']). The application merges such chunks after retrieval, returning only one entry per document to avoid redundancy.
Results
Some were as expected, some surprised us.
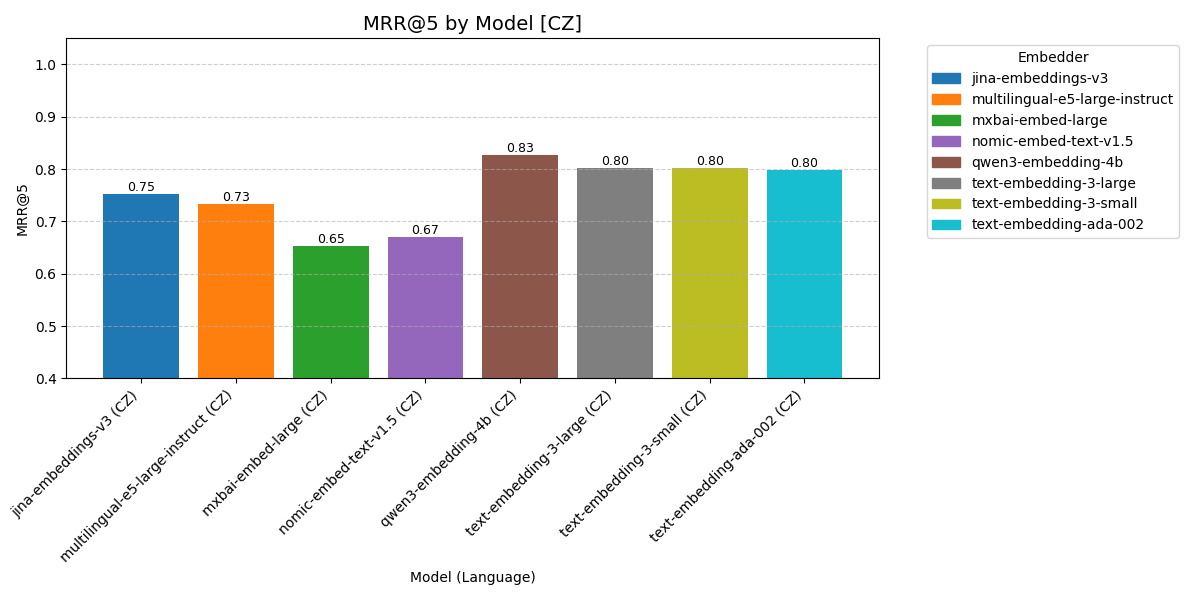
Czech queries
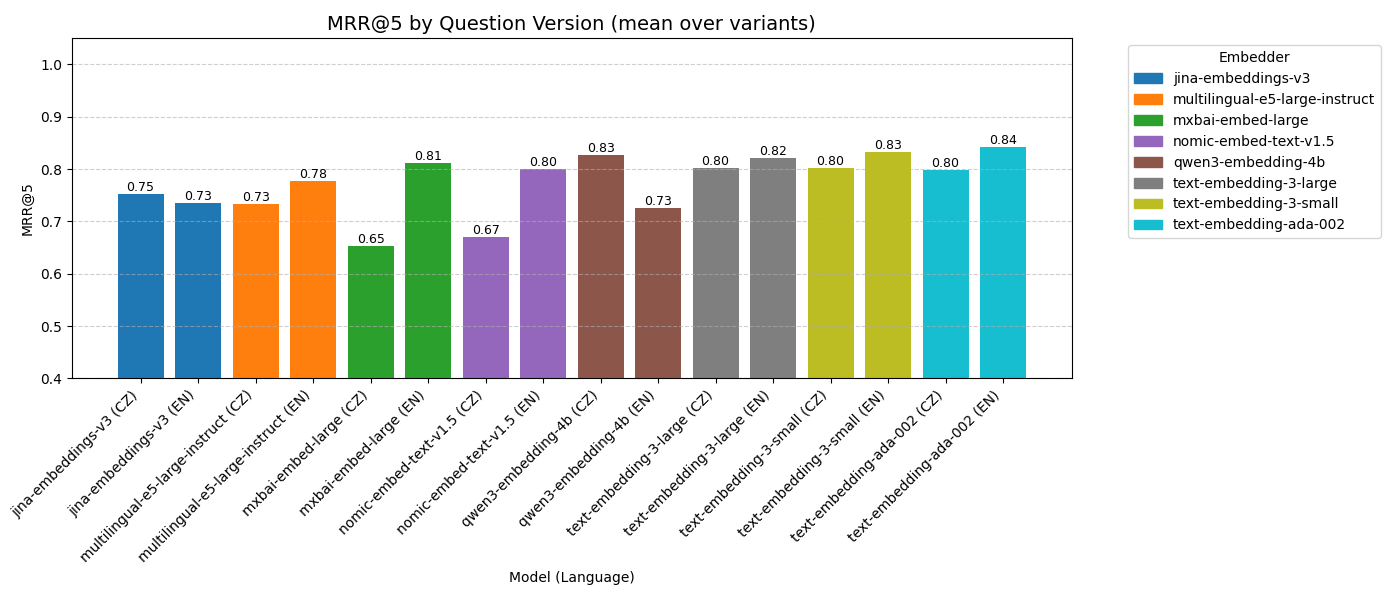
Models varied in handling Czech queries. The best one for Czech was qwen3-embedding-4b, which has overall MRR@5 equal to 0.83 – that means that the correct document was on average returned at 1/0.83 = 1.2 position.
Not much worse were all the models from OpenAI.
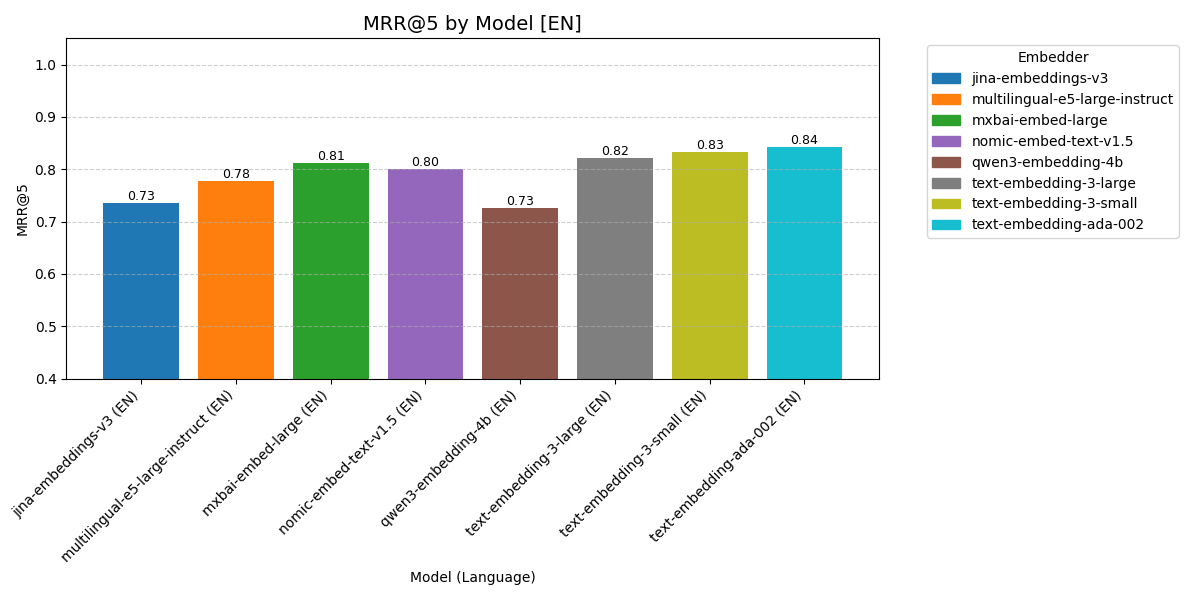
English queries
The best performance on our documentation showed OpenAI models. It is interesting that their performance was quite similar: more dimensions does not necessarily mean better model.
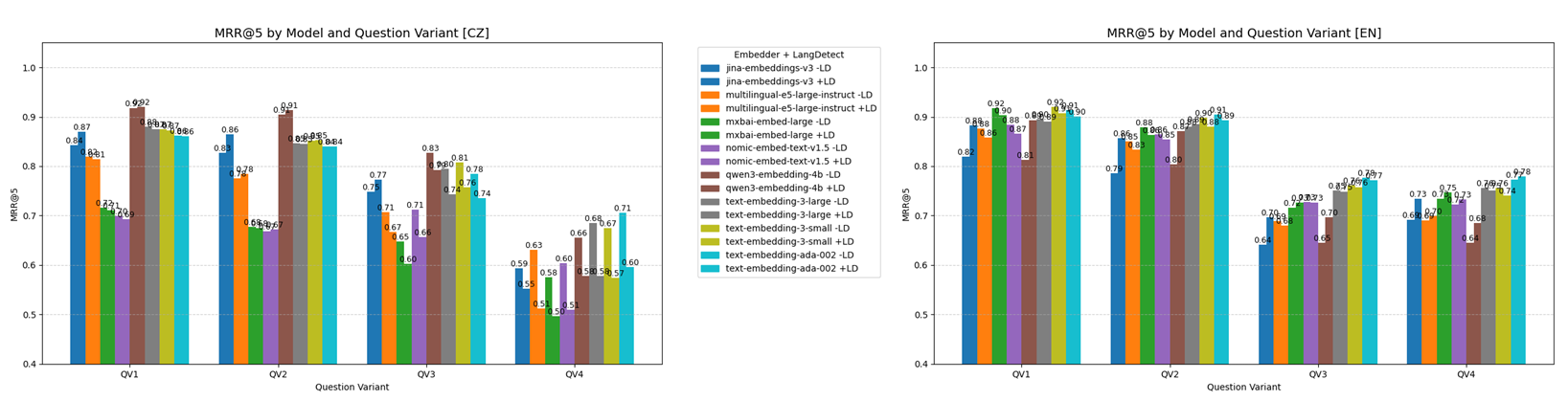
Language detection
Automatic language detection significanty improved only results of jina-embeddings-v3🔵 and qwen3-embedding-4b🟤 models in english queries. After visualizing the embedding space, we found partial explanation for why only these two models benefited.
Also notice that language detection on Czech queries of question variant 4 (short keywords) worsen the retrieval a lot. The reason probably is that by searching for specific program names or errors (“konfigurace Omero ingress”), English is mostly used and detected and therefore, correct Czech document can never be retrieved.
Automatic language detection did not enhance cases where the embeddings of the same document in Czech and English were very different (i.e., far apart in the embedding space). As a result, even without narrowing the search to a specific language (e.g., Czech), the embedding in the other language (e.g., English) would still have scored too low in similarity to be selected, even without language filtering.
In the figure below, we plotted embeddings of Czech (blue) and English (orange) documents across several models using PCA. Dashed lines connect translations of the same document.
Most models show clear separation between languages, meaning Czech and English embeddings are far apart (even though the meanings are the same, the embeddings are shifted). This explains why language detection did not improve them – they separate languages on their own. However, jina-embeddings-v3 and qwen3-embedding-4b keep translations closer together which explains why their performance was improved.
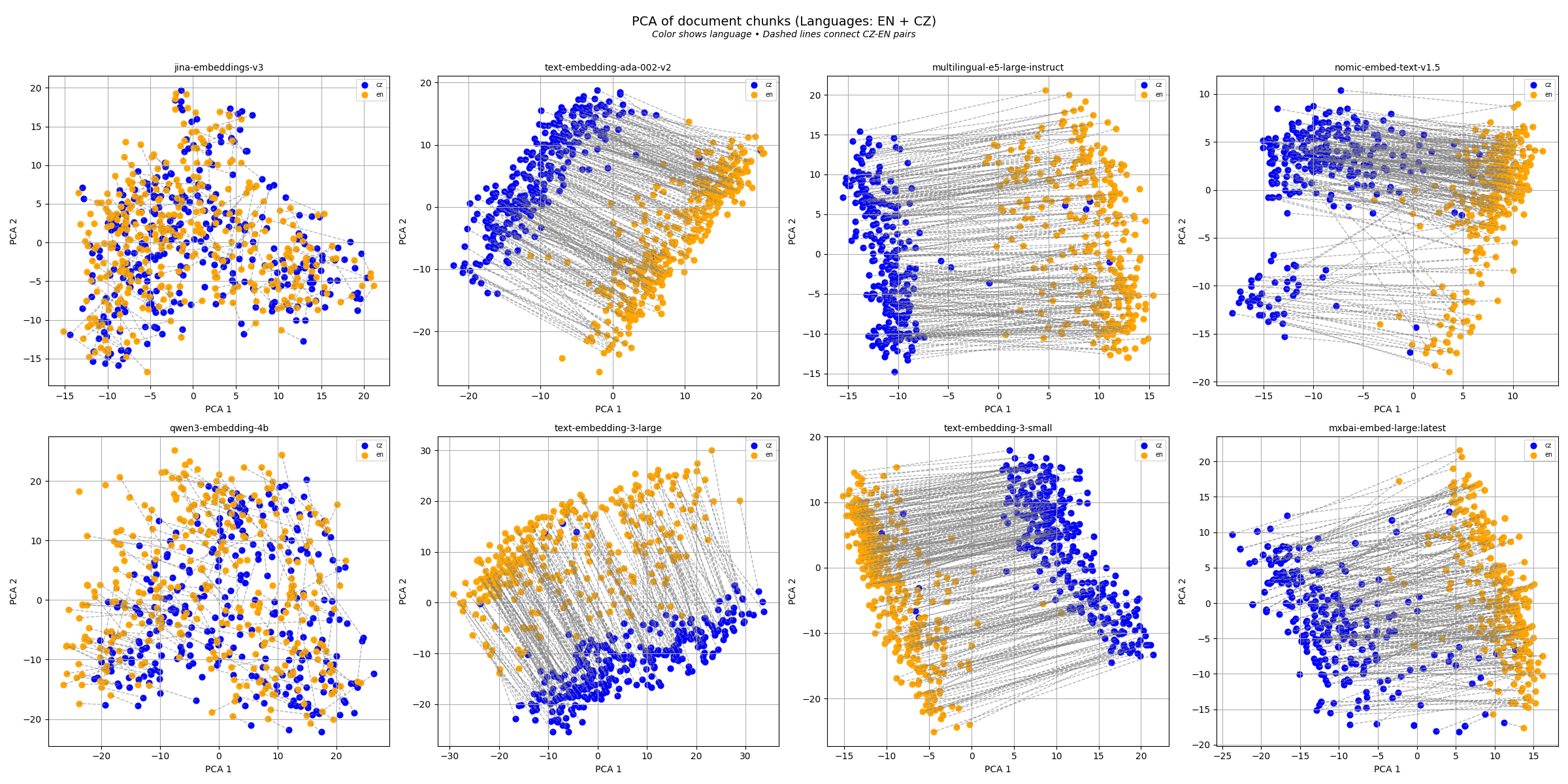
Implementing automatic language detection helped in cases where model does not distinguish embedding between languages.
Chunks
Each document is split into chunks, which are individually embedded and compared to the query (see here). However, when returning results through the API, all matching chunks from the same document are combined to reconstruct the full document. Therefore, the chatbot searches for the answer within the context of the entire original document – so it’s generally better if chunks from the same document are embedded close together, as this reflects semantic consistency and improves retrieval accuracy. On the other hand, if a document contains multiple unrelated sections (e.g., FAQ or multi-topic pages), chunk separation might be desirable – it is better to treat each section as its own “document.”
This finding suggests a possible pattern worth exploring, but more testing is needed before drawing conclusions.
Question variants
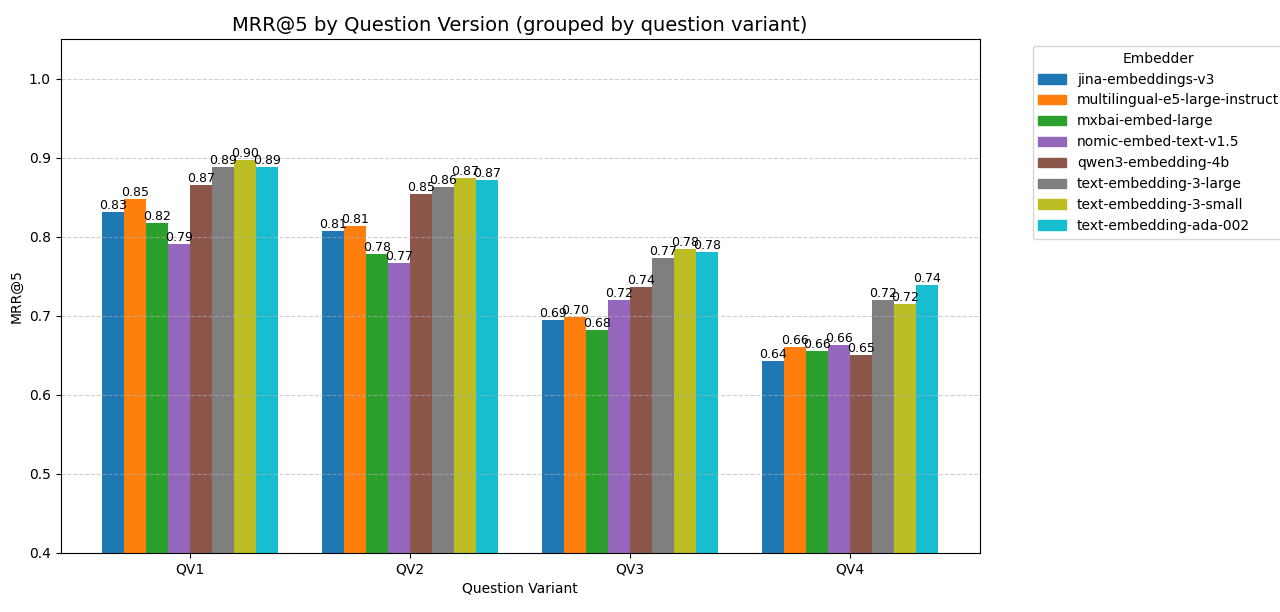
The chart shows that the way a question is phrased significantly affects retrieval performance. Longer and more detailed questions (like in QV1 and QV2) generally led to better results, as they provided more context for matching relevant content. Shorter, user-like prompts (QV3) caused a slight decline, while very brief or incomplete queries (QV4) proved most difficult for the models to handle. In short, clearer questions help retrieval – vague or keyword-only queries make it harder for models to find the right document.
The best model?
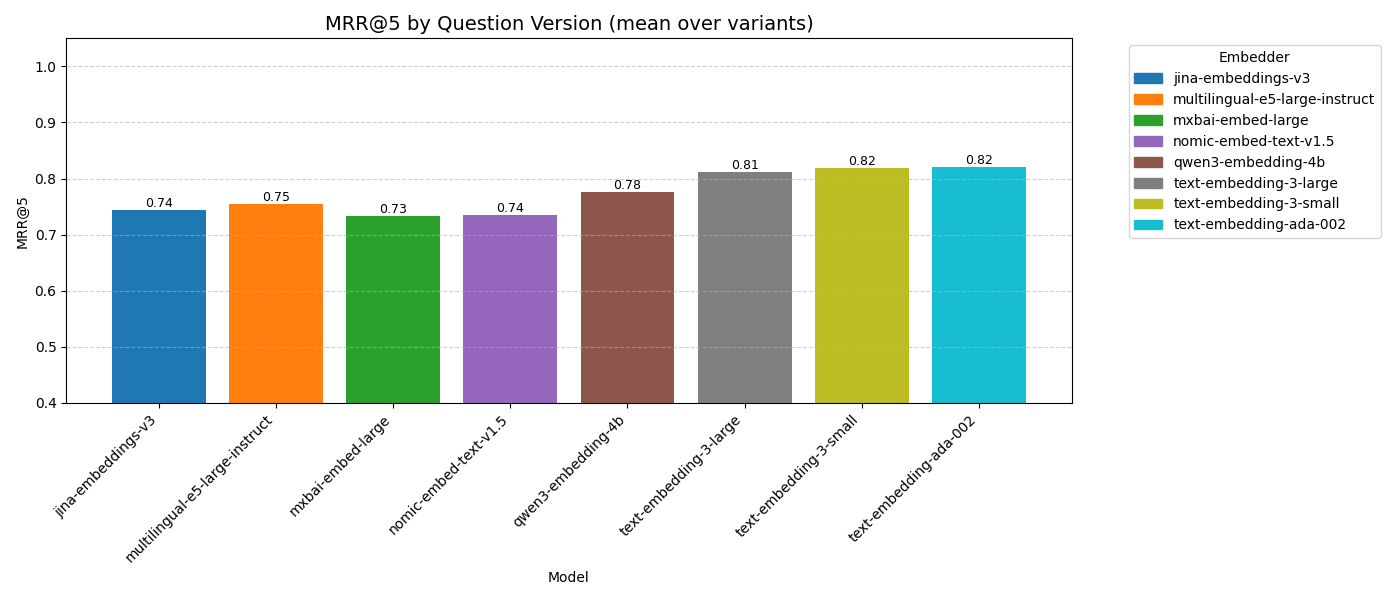
Overall, all three models from OpenAI performed the best for CERIT-SC documentation, followed by qwen3-embedding-4b. Different performances suggest that we may further try using different model for different language.
Conclusion
To sum up, we compared several embedding models to see which one retrieves the most relevant documents based on a user’s question. The results showed clear differences between models – some worked better for Czech, others for English. We also saw that longer, more specific questions helped with finding the right documents. Language detection improved results of only specific models, since for others Czech and English versions of the same content were already far apart in the embedding space. These findings help us better understand how embedders behave and guide us in choosing the right models for future use.