BeeGFS in MetaCentrum
Posted on July 8, 2025 (Last modified on July 10, 2025) • 6 min read • 1,267 wordsPerformance of High-Speed Filesystem for Demanding Computations
What is BeeGFS?
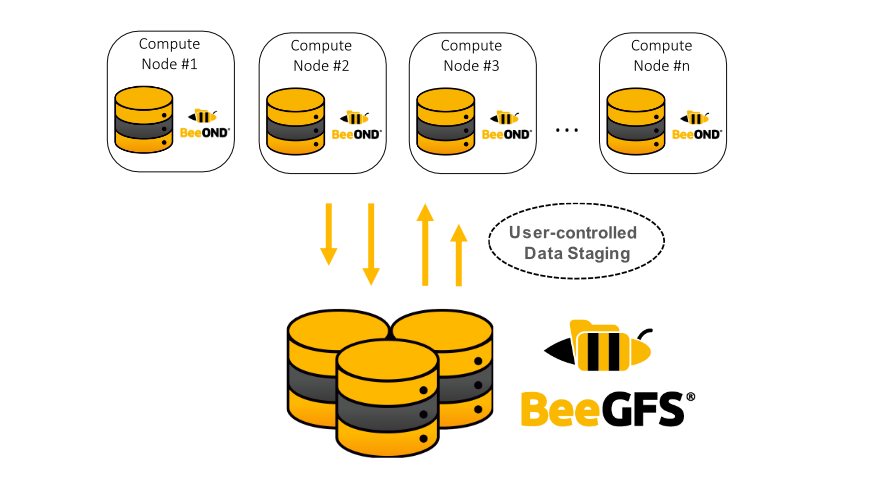
BeeGFS (Beyond Extensible Enterprise File System) is a parallel distributed filesystem designed specifically for the needs of high-performance computing (HPC). It is used in computing clusters, scientific simulations, machine learning, genomics, and everywhere large datasets and fast parallel access are essential.
BeeGFS combines multiple storage servers to provide a highly scalable shared network file system with striped file contents. This way, it allows users to overcome the tight performance limitations of single servers, single network interconnects, a limited number of hard drives, etc. In such a system, high throughput demands of large numbers of clients can easily be satisfied, but even a single client can benefit from the aggregated performance of all the storage servers in the system.
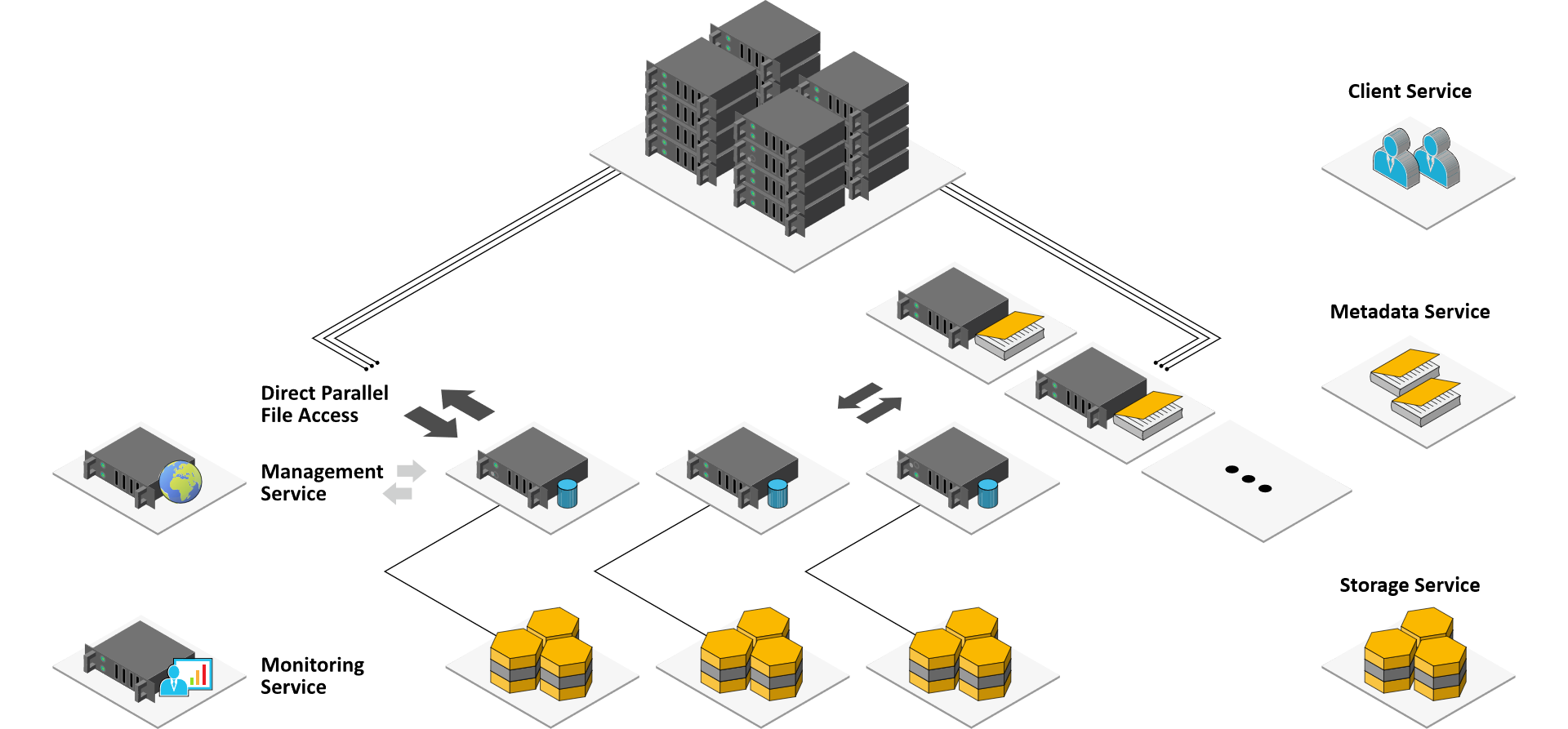
This is made possible by a separation of metadata and file contents. While storage servers are responsible for storing stripes of the actual contents of user files, metadata servers do the coordination of file placement and striping among the storage servers and inform the clients about certain file details when necessary. When accessing file contents, BeeGFS clients directly contact the storage servers to perform file I/O and communicate with multiple servers simultaneously, giving your applications truly parallel access to the file data. To keep the metadata access latency (e.g., directory lookups) at a minimum, BeeGFS also allows you to distribute the metadata across multiple servers so that each of the metadata servers stores a part of the global file system namespace.
On the server side, BeeGFS runs as normal user-space daemons without any special requirements on the operating system. The BeeGFS client is implemented as a Linux kernel module which provides a normal mount-point so that your applications can directly access the BeeGFS storage system and do not need to be modified to take advantage of BeeGFS. The module can be installed on all supported Linux kernels without the need for any patches.
Key Advantages
- Access from Multiple Machines – One of the primary benefits of BeeGFS is the ability to access it from multiple machines, allowing for:
- Large Parallel Computations: BeeGFS enables large parallel computations, where multiple machines can access data simultaneously, significantly increasing performance.
- Sequential Computations: BeeGFS also enables sequential computations, where intermediate results left in the scratch directory can be picked up by subsequent computations, eliminating the need to copy data to permanent storage or require execution on the same machine as the previous step.
- Scalability – As the number of nodes increases, BeeGFS’s performance scales accordingly, making it an excellent choice for large-scale HPC applications. BeeGFS efficiently handles massive datasets (tens of terabytes to petabytes) and scales with your needs. Its multithreaded design and native RDMA support enable high-performance and redundancy, making it perfect for large-scale research projects and HPC applications.
- Distributed Architecture – BeeGFS avoids bottlenecks by distributing file contents and metadata across multiple servers, ensuring high performance and scalability for large systems and metadata-intensive applications.
- High Throughput – BeeGFS is optimized for parallel input/output operations, ensuring fast and efficient data access.
- Fault Tolerance – BeeGFS is designed to be highly fault-tolerant, with features such as automatic failover and self-healing, ensuring that data is always available and minimizing downtime.
Limitations
- No native full POSIX distributed locking (may cause issues with applications relying on strict file locking),
- No disk quotas (limits on storage usage per user or group),
- Sensitive to node failures in the cluster (can impact performance and availability),
- Potential software layer errors (may require troubleshooting and debugging),
- More complex administration compared to traditional file systems (requires specialized knowledge and expertise).
Implementation in MetaCentrum
At MetaCentrum, we’ve adopted BeeGFS to meet the increasing challenges of data-intensive research across various scientific disciplines.
BeeGFS is available as a temporary working directory via the scratch_shared resource on cluster bee.cerit-sc.cz.
In contrast to local scratch spaces on other clusters, our implementation of BeeGFS in MetaCentrum features a RAID configuration that protects jobs from the consequences of a single disk failure, even on the local scratch space. This comes at the cost of slightly lower sequential write performance compared to sequential reads. Similarly, our shared scratch space on cluster bee is also protected against disk failures. However, in the event of a node failure, data on the shared scratch space may become temporarily inaccessible. This design decision was made to ensure the reliability and availability of data on our shared storage systems.
When to Use BeeGFS in MetaCentrum
BeeGFS is particularly well-suited for demanding jobs that require:
- Work with large files or a huge number of small files – efficiently handle massive datasets, making it an ideal choice for applications that require fast and scalable storage.
- Utilize many threads or processes that read or write in parallel – allows for high-performance and concurrent access to data, making it perfect for applications that require simultaneous reads nd writes.
- Spanning multiple compute nodes – can handle workloads that span multiple compute nodes, allowing for seamless scalability and performance.
- Sequential computations with intermediate results – well-suited for workflows where subsequent computations can pick up intermediate results left in the scratch directory, eliminating the need to copy data to permanent storage or run on the same machine as the previous step.
Typical Use Cases:
- High-Performance Computing (HPC) – BeeGFS is designed to efficiently handle large files and parallel input/output operations, making it an ideal choice for scientific computing workloads.
- Machine Learning and AI – With BeeGFS, you can train machine learning models faster by accessing large volumes of data with high-throughput and low-latency.
- Simulations, Rendering, Genomics, and Big Data Research – BeeGFS is perfect for handling massive datasets, such as those found in 3D rendering, complex simulations, genomic sequencing, and big data research.
📊 Performance Results: BeeGFS vs. Local Scratch
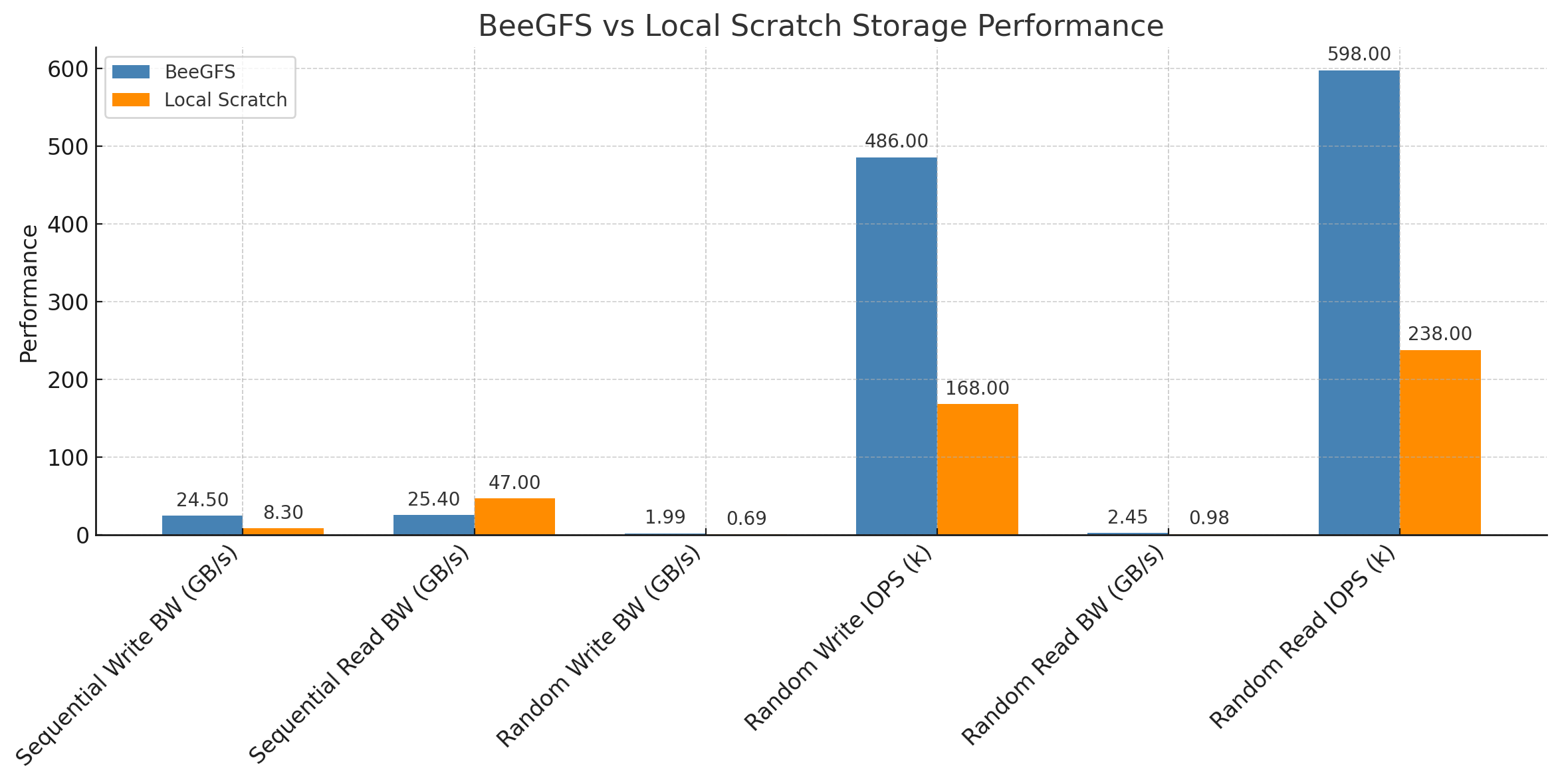
We compared the performance of BeeGFS (scratch_shared on the bee cluster) and node-local scratch (scratch_local) using synthetic benchmarks with parallel I/O.
| Test | BeeGFS (128 threads) | scratch_local (8 threads) | Comment |
|---|---|---|---|
| Sequential Write | 22.8 GiB/s (24.5 GB/s) | 7946 MiB/s (8.3 GB/s) | BeeGFS ~3× faster (massive parallelism) |
| Sequential Read | 23.7 GiB/s (25.4 GB/s) | 43.8 GiB/s (47.0 GB/s) | Local disk faster in read (low overhead) |
| Random Write | 486k IOPS, 1899 MiB/s | 168k IOPS, 656 MiB/s | BeeGFS ~3× more IOPS |
| Random Read | 598k IOPS, 2335 MiB/s | 238k IOPS, 930 MiB/s | BeeGFS leads in random access |
It’s worth noting that BeeGFS’s peak performance is achieved by utilizing resources from multiple nodes, which assumes a favorable statistical interleaving of disk-intensive and less demanding tasks. Unlike local scratch, it’s unlikely to achieve such high performance on all nodes in the cluster simultaneously.
Here’s a bar chart comparing BeeGFS and Local Scratch across key performance metrics. As shown:
- BeeGFS dominates in random I/O (both read and write).
- Local Scratch excels in sequential read bandwidth.
Interpretation:
- BeeGFS BeeGFS excels at random I/O and sequential write performance
- Local scratch excels in sequential read performance and total read volume on single node.
- Use BeeGFS for workloads with high random I/O and mixed-read/write patterns.
- Use local scratch for read-heavy sequential workloads (e.g., data analysis).
To compare scratch storage types in MetaCentrum:
| Scratch Type | Speed | Best For |
|---|---|---|
scratch_shm |
🟢 Fastest (RAM) | Ultra-fast, short-lived temp data |
scratch_local |
🟡 Very fast (local SSD/HDD) | Single-node jobs with high throughput |
scratch_shared |
🔵 Scalable parallel I/O | Multi-node, parallel jobs needing fast I/O (BeeGFS) |
Summary
If your computational work involves:
- Processing large datasets in parallel,
- High-throughput or high-IOPS requirements,
- Multi-node jobs in an HPC environment,
- Sequential computations with sharing intermediate results.
then BeeGFS is an excellent choice. With BeeGFS, you can achieve multi-GB/s throughput and hundreds of thousands of IOPS, helping your applications run faster and more efficiently.
More details: MetaCentrum Scratch Documentation)